Researchers look at the advantages and disadvantages of freshly available reasoning models in a study published by Apple on Saturday. These models, also referred to as large reasoning models (LRMs), “think” by using more computation to resolve challenging issues. Nevertheless, the study discovered that a complexity problem plagues even the most potent models. Instead of using more computation, as the models are trained to do, researchers found that when an issue is extremely complicated, the models completely collapse and give up on it.
Researchers claim that when faced with three regimes of complexity, both LRMs and large language models (LLMs) without thinking capability behave differently in a paper titled “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity,” which was posted on Apple’s website.
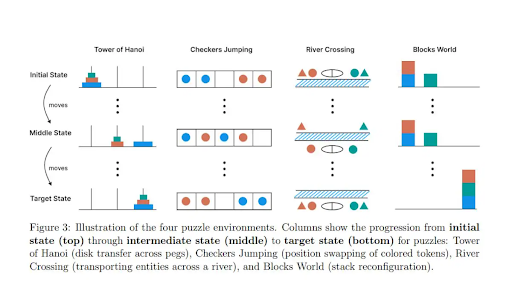
Low, medium, and high complexity problems are the three complexity regimes that have been discussed in the study. The researchers chose to employ a number of puzzles that can increase in difficulty in order to examine how LLMs and LRMs perform while handling a broad range of complications. The Tower of Hanoi was one such puzzle.
Three pegs and multiple disks make up the Tower of Hanoi, a mathematical puzzle. To form a pyramid, disks are stacked in decreasing order of size. The goal of the puzzle is to move each disk one at a time from the leftmost peg to the rightmost peg. The catch is that a larger disk should never be stacked on top of a smaller disk. Children between the ages of six and fifteen are frequently the intended audience for this easy problem.
For this experiment, two reasoning models and their non-reasoning counterparts were selected by Apple researchers. Claude 3.7 Sonnet with Thinking and DeepSeek-R1 were the LRMs selected, and Claude 3.7 Sonnet and DeepSeek-V3 were the LLMs. A maximum of 64,000 tokens per person was allocated to the thinking budget. The experiment’s goal was to verify not only the ultimate accuracy but also the logic accuracy of the methods used to solve the puzzle.
Disk sizes were maintained between four and ten for the medium complexity assignment, whereas up to three disks were added for the low complexity task. Lastly, there were eleven to twenty disks in the high complexity challenge.
In completing the low complexity challenge, the researchers saw that LLMs and LRMs shown equal competence. Given the additional computational budget, reasoning models were able to solve the puzzle more precisely as the complexity grew. However, it was discovered that both models had a total collapse of reasoning when the tasks approached the high complexity zone.
It was also claimed that the same experiment was conducted again with additional models and puzzles, including Blocks World, River Crossing, and Checkers Jumping.
The issues raised by a number of other artificial intelligence (AI) researchers are emphasized in Apple’s study. While reasoning models are capable of generalizing within their distributed datasets, they struggle to “think” when faced with problems that are beyond their scope. They either attempt to discover shortcuts to solve the problem or give up and collapse entirely.
“Established mathematical and coding benchmarks are the main focus of current evaluations, which place an emphasis on final solution accuracy. However, the corporation stated in a post that this evaluation paradigm frequently suffers from data contamination and does not offer insights into the structure and quality of the reasoning traces.
Related Reading
More contextual TechBooky stories selected from tags, categories and article context.
Paul Balo is the founder of TechBooky and a highly skilled wireless communications professional with a strong background in cloud computing, offering extensive experience in designing, implementing, and managing wireless communication systems.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.
{kind=link}