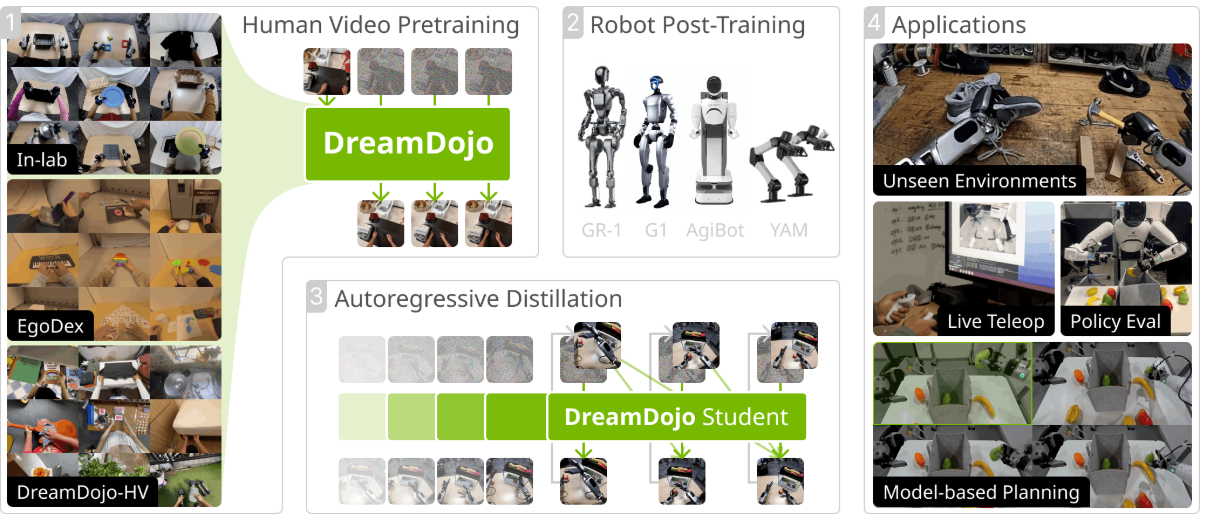
A research team led by Nvidia has introduced DreamDojo, an AI system built to help robots learn how to handle the physical world by watching vast amounts of human video. The goal is to cut the time and cost of training advanced robots, including humanoid machines, by giving them a powerful “world model” before they ever touch real hardware.
The work, released this month and detailed in an academic paper, brings together Nvidia and collaborators from UC Berkeley, Stanford, the University of Texas at Austin and several other institutions. The researchers describe DreamDojo as “the first robot world model of its kind that demonstrates strong generalization to diverse objects and environments after post-training.”
DreamDojo is trained on what the team calls a large-scale video dataset of human activity, captured from an egocentric (first-person) perspective. This dataset, named DreamDojo-HV, comprises 44,000 hours of diverse human egocentric videos.
According to the project documentation, DreamDojo-HV is currently the largest dataset used for world model pretraining. In terms of scale, the researchers say it represents a significant jump over prior efforts, describing it as:
15 times longer in total duration
96 times more distinct skills
2,000 times more unique scenes
These comparisons are made relative to what they identify as the previously largest dataset used for training robot world models. The expanded duration, skill diversity and scene variety are meant to give DreamDojo a broader understanding of how humans move, manipulate objects and operate in different environments.
DreamDojo’s training process runs in two distinct phases, designed to separate general physical learning from robot-specific fine-tuning.
In the first phase, the system “acquires comprehensive physical knowledge from large-scale human datasets by pre-training with latent actions.” In practice, this means DreamDojo is exposed to the 44,000 hours of egocentric human video and learns an internal representation of how the world behaves, without being tied to any single robot body.
In the second phase, the model is “post-trained on the target embodiment with continuous robot actions.” Here, the general world understanding derived from human video is adapted to a particular robot platform. The system learns how to translate its learned representation of physics and interaction into the continuous control signals that drive a specific robot.
The researchers argue that this two-step setup allows DreamDojo to first develop a broad understanding of objects, environments and actions, and then specialize that understanding for a given robot. They highlight the resulting “strong generalization to diverse objects and environments after post-training” as a key outcome.
By relying on such a large-scale human video corpus in the first stage, DreamDojo is intended to reduce the amount of robot-specific data and engineering typically required to get capable behaviour in the real world. The system is presented as a way to front-load much of the learning into an offline, video-based world model, which is then adapted more efficiently to actual machines.
Paul Balo is the founder of TechBooky and a highly skilled wireless communications professional with a strong background in cloud computing, offering extensive experience in designing, implementing, and managing wireless communication systems.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.










{kind=link}